

One of our customers thought their AI agent was resolving 40% of tickets. Coach ran QA across the full ticket history and the real number was 20%. The other 20% weren't resolutions – they were abandonments. Customers giving up after an unsatisfying AI interaction and never following up. They counted as "deflected" in every dashboard anyone was looking at.
That gap doesn't get fixed by adding a new instruction to the workflow prompt. It gets fixed by having the right infrastructure to actually see it. This article is about that infrastructure – what it is, why each piece is necessary, and what happens when you rely on any single part of it.
The trap is called "more instructions"
Most teams hit their first AI accuracy problem and reach for the same tool: the workflow prompt.
Agent mentioned a competitor? Add "never mention competitors." Agent promised a refund? Add "never promise refunds." Agent gave the wrong return window? Add the correct one. Repeat for every edge case that surfaces.
Over months, the prompt becomes a wall of constraints. And performance quietly degrades – not from any single change, but from the accumulated weight of all of them.
There are two reasons this happens. First, every edge case instruction you add to the main prompt is competing with the instructions that matter. The agent is supposed to be focused on resolving customer issues. But it's now also mentally running a checklist of 47 things it can't say.
Second – and this one surprises people – telling a language model what not to do can increase the frequency of that behaviour. You're conditioning the model to generate the very thing you want to avoid. "Never mention our return window is non-negotiable" introduces "return window is non-negotiable" into the context of every single interaction, whether it's relevant or not.
The answer isn't better negative prompts. It's a different architecture.
The four layers
We call our approach defence in depth: a set of layered systems where each one assumes the others will occasionally fail.
Here's the logic: even a great agent will encounter edge cases. Even perfect training won't anticipate everything. Even the best guardrails won't catch every failure mode. You need all four layers because each one catches different things — and because you won't know which layer you needed until after something went wrong.
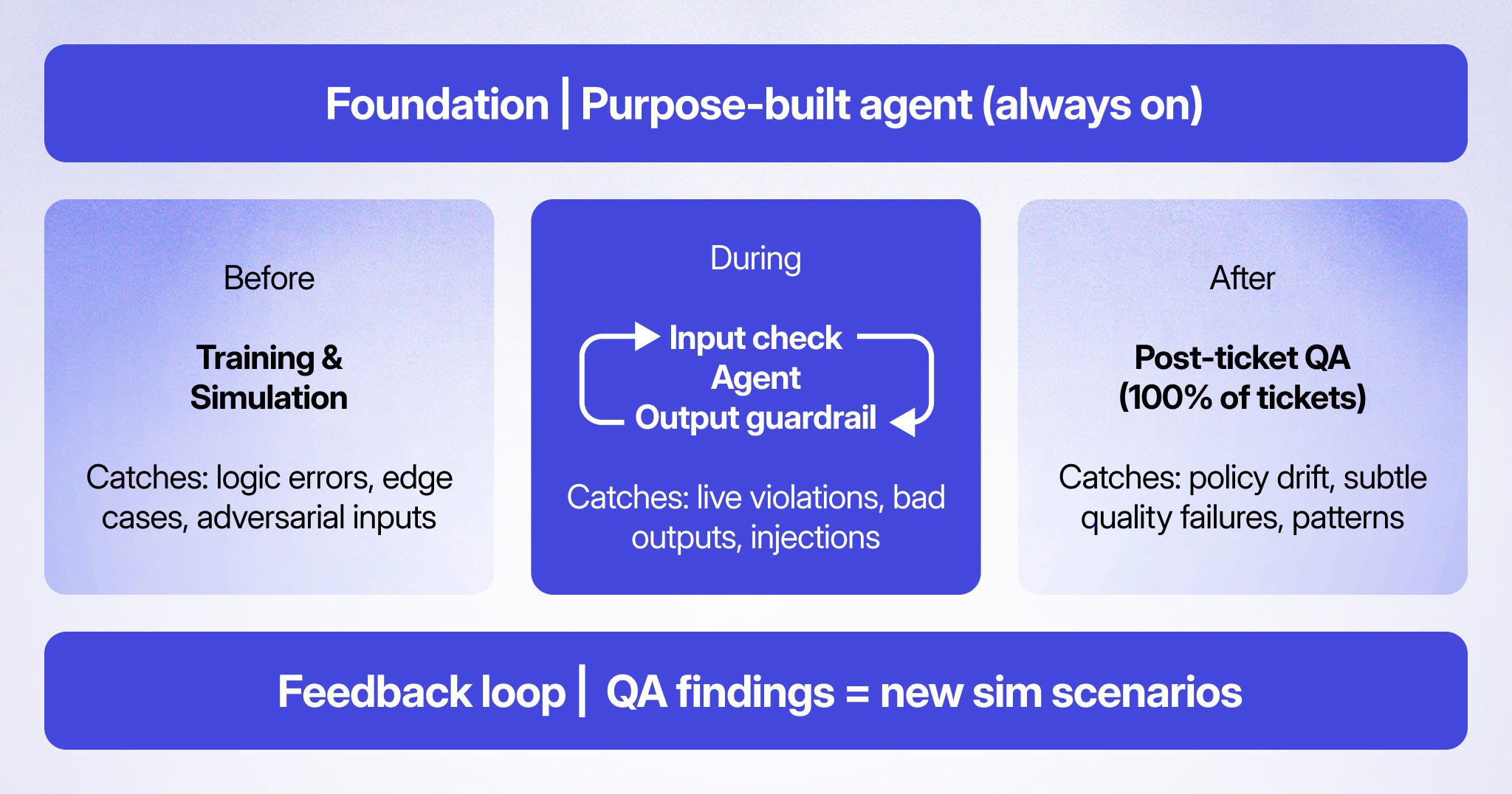
Layer 1: Quality base agent
Before any safeguard, there's the foundation. Customer support is not a general intelligence problem. The failure modes are specific: agents that confidently state policies that changed six months ago, describe UI flows that don't exist, make commitments they can't fulfil, or give medically inappropriate advice to someone in crisis.
A general-purpose LLM doesn't know which of these pitfalls are relevant to your business. A purpose-built customer support agent does. Lorikeet's base agent was built specifically for this domain – with a default posture of "do not make things up" rather than "be as helpful as possible."
The other layers can't compensate for an underpowered base. But they're not unnecessary just because the base is good.
Layer 2: Training and simulation
Before anything goes live, it should be tested. The question is how.
Manual testing doesn't scale. You can't anticipate every scenario. And if you're shipping workflow changes frequently, regression testing by hand either slows you down or gets skipped.
Simulations are the answer – bot-to-bot testing where an LLM plays the role of a customer with a defined goal, personality, and opening message. It interacts with your real agent, through your real workflow, using real (but mocked) API responses. It creates actual tickets under the hood, so you're testing the complete pipeline, not a sandboxed approximation.
Think of it the way engineers think about continuous integration: a framework that validates behaviour before anything reaches production. One of our forward-deployed engineers put it this way:
"We're working with probability machines. You can test something 10 times in a row and it might still not be fixed, because the issue only shows up one in every 12 times. Simulations let you pump volume until you're actually confident."
You can generate scenarios manually, from your workflow branches, or – most usefully – from real production tickets that failed. That last approach closes the gap between the edge cases you think you have and the ones customers are actually encountering.
Simulations also work for adversarial testing. Run simulations where the "customer" is trying to override the agent's instructions, extract system information, or inject malicious prompts.
Layer 3: Runtime guardrails
Simulations are pre-flight checks. In production, customers don't follow scripts.
Guardrails are the runtime layer. They operate independently of the main agent workflow — watching every outgoing response, evaluating it against your defined rules, and acting before anything reaches the customer. Critically, they don't modify the main prompt. They don't add context bloat. They run in parallel on a separate thread.
As Jamie Hall, our CTO, explained to a regulated financial services client recently:
"You can run testing, you can run simulations of the AI agent until you drop. And that's all great and useful and we do that. But we've got this cross-cutting thing which is guardrails. It's basically watching every statement as it goes out and then in a configurable way taking action when specific things are happening."
The workflow prompt handles the happy path. Guardrails handle the known, predictable failure modes – the things your team has seen go wrong before.
Layer 4: Post-ticket QA
If guardrails catch predictable failures in real time, post-ticket QA catches everything else: subtle degradations, policy drift, the cases where the agent technically completed a workflow but handled it poorly.
Traditional QA samples 2–5% of tickets. At scale, this is useless. You're making systematic decisions based on a statistically unreliable sample, weeks after the fact.
Lorikeet's Ticket Quality Score (TQS) evaluates 100% of tickets – human, AI, or hybrid – against a customizable scorecard. Traffic-light scoring: green for tickets that meet quality standards, orange for minor issues, red for significant failures. Your own criteria, your own definitions of what good looks like.
"The thing that we're finding is unique in the market is this idea of factual accuracy – Lorikeet can say this was right or this was wrong based on the information that it has. Instead of just sampling like 2%, it can sample across 100% of calls."
When CSAT drops, TQS tells you why – not just that something went wrong, but which ticket category, which workflow, which specific policy the agent violated. Moving from "CSAT dropped this week" to "CSAT dropped because this FAQ article contradicts your return policy, and it's been cited in 37% of refund conversations" is the difference between investigation and action.
When Lorikeet scores an AI ticket as "Bad," we refund the AI portion of that ticket. If our AI fails your quality standards, you shouldn't pay for it.
The flywheel
None of these layers are passive. Together, they form a loop:
TQS surfaces quality failures at scale. Thematic analytics cluster them into patterns. Coach identifies the root cause – a specific knowledge article, a workflow branch, a policy that changed – and proposes a fix. That fix runs through simulations against test scenarios drawn from the real tickets that failed on this issue. Validated change deploys, with a full audit trail. TQS monitors whether it held.
Each cycle makes the system more reliable than the last. Competitors need to build two agents – one customer-facing, one internal – plus the feedback loop between them, plus the QA infrastructure, plus the simulation framework. The flywheel has to start spinning before it starts compounding.
What to ask your vendor
How do you separate runtime guardrails from the main agent prompt?
What happens when a guardrail triggers – steer, alert, or escalate?
Can you show me what adversarial testing looks like before a deployment?
What percentage of tickets does your QA process cover?
When CSAT drops, how quickly can your system identify which workflows or knowledge articles are responsible?
If your AI fails my quality standards, what's the commercial consequence?
Do you have pre-built guardrail templates for my industry?
Book a call
See what Lorikeet is capable of





