

There’s one question on every support leader’s mind when they are deciding whether to scale support operations: is the quality there and is it reliable?
Sampling and reviewing a handful is sufficient when ticket volume is manageable. It provides a sense of quality that can be averaged across remaining tickets, but it’s not reliable when handling thousands of conversations.
In this context, failures of process are rarely picked up. A human or AI agent promises a customer a fee waiver the policy doesn’t allow, the customer doesn’t complain because they got the response they wanted, and the likelihood a reviewer pulls the ticket is low because it’s one of many. The issue sits there, invisible.
Auto QA is built to catch exactly this, and it does so by scoring every single ticket.
Sampling at scale
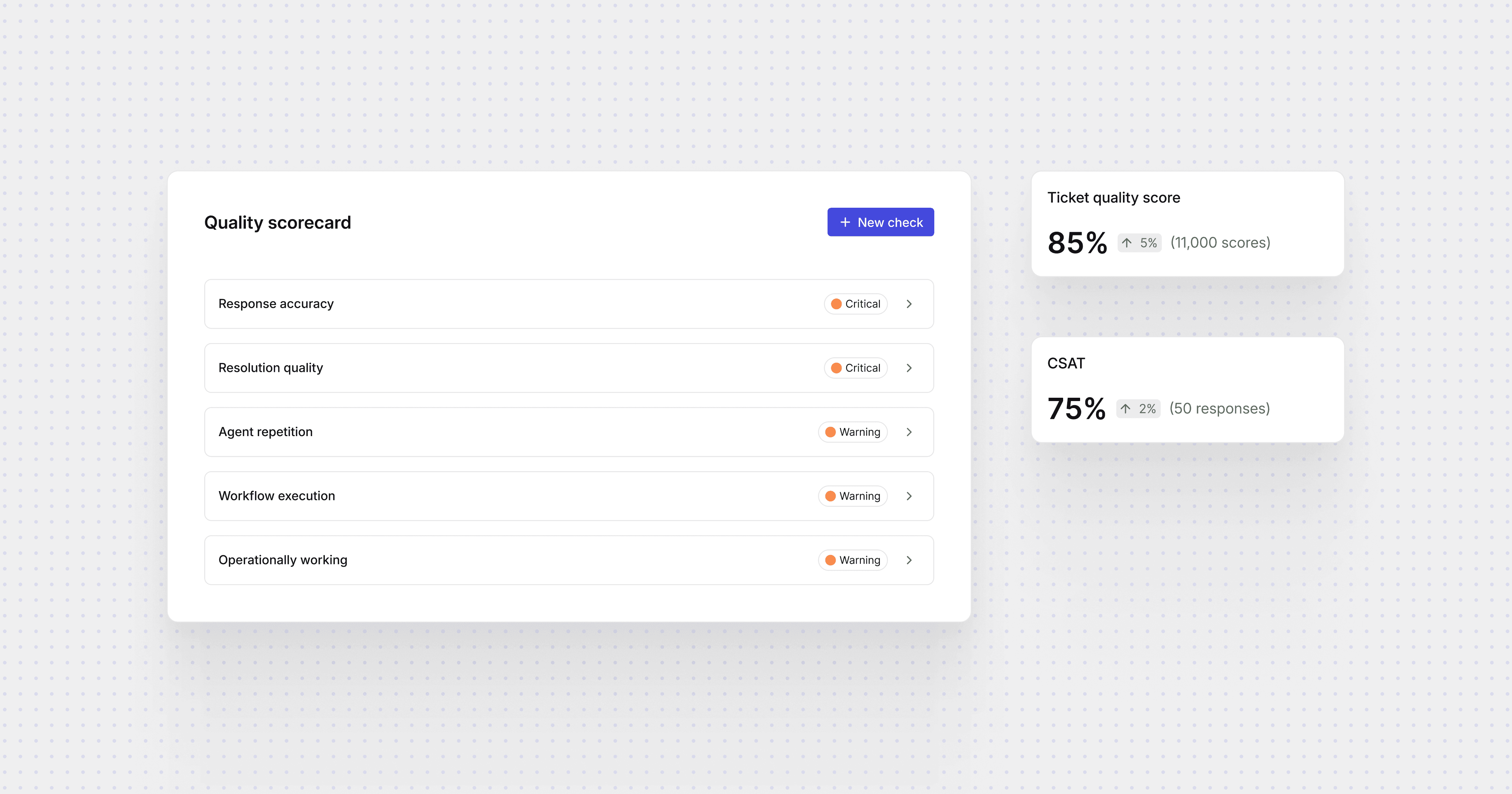
AI customer support enables ticket volume to climb without human teams growing. QA teams now handle thousands of conversations a week and reviewing a hundred of them is grading 1-3%. Issues in the other 97% stay invisible until a customer escalates or an auditor asks. In regulated support, a bad ticket can become a compliance breach.
The obvious question about scoring every ticket automatically is whether scores are genuinely reliable. To guarantee this, we built proactive recall into the system. Auto QA catches ~99.7% of bad tickets and when a check is unsure, proactive recall holds the sample and flags for review by a human. Your team reviews and their feedback is memorized to sharpen scoring.
The outcome is a short list of conversations that specifically deserve a human’s attention instead of a random sample. Auto QA safeguards the reviewer’s efforts, pointing them only at high judgement tickets.
Building inside the system
A handful of existing QA tools sit outside of support systems and act as third-party auditing methods. These tools see two things: the transcript and the outcome. They read what was said and whether the customer seemed happy. They can’t see whether the agent called the refund API, or which knowledge article it read before answering. They lack the vital context required for durable reliability.
Auto QA is built inside the system that handles tickets, so it sees both. A custom check reads the connected SOPs and policy documents and judges the answer against them. If a disputes policy is a 30-day window and the agent told a customer 14 days, the check fails and the reasoning cites the exact article that contradicts it.
That’s the difference between grading form and grading correctness. Tone and process recognize the agent sounded right. Whether it was actually right can only be checked against the source the answer lives in.
One standard, everywhere
Because the checks are written in plain language and read knowledge, they apply to any ticket, whoever handled it. The same identity check, the same disputes-window check, runs on the AI agent and on the human team.
For teams running AI as one layer of their operation, it will likely be their first clean comparison, enabling them to see where the AI underperforms the human team and where it does better, at the ticket level rather than by sentiment or sample. Sometimes the answer is that the human was the one off-policy.
Proactive improvement with Coach
A score on its own only tells you something went wrong. With Lorikeet, every failed check feeds Coach, our operations agent, which surfaces the pattern behind it: a workflow failing a correctness check on roughly one in ten tickets, or a brand’s knowledge base that has drifted from the policy doc. Coach automatically fixes the issue, lifting the next ticket’s score and, as your team marks checks right or wrong, the scoring sharpens to your quality bar.
Book a call
See what Lorikeet is capable of
Share this article





